시작
알고리즘 스터디를 진행하면서 불편한 점이 있었습니다. 코딩 문제 풀이 사이트가 엄청 많다는 점입니다. 한 곳에서 몰아서 보고 싶은 욕구가 강렬하게 들었습니다. 무언가 만들고 싶다는 생각이 오랜만에 들었습니다. 알고리즘 스터디에서 개별 문제 선정할 때 미약하게나마 도움이 될 것은 느낌이 들어서 프로젝트를 계획해 보았습니다.
계획
만들고 싶은 프로그램에 대한 요구 사항과 하고 싶은 것들을 하나씩 적어보았습니다.
- 프로그램 최종 목표는 스터디에서 매주 문제 리스트업에 도움이 되고 싶다. 도움 안돼도 상관없다.
- 최근에 웹 스크래핑을 해보았는데 적용해 볼 기회인 것 같다. python 이용해 스크립트를 작성하자.
- 데이터 저장은 디비에 저장하고 데이터 형식이 자유로운 MongoDB 에 저장하자.
- 웹 사이트를 구현하는 것은 규모가 크고 데이터 쉽게 접근할 수 있는 환경이 제공되어야하니 오픈 소스 Bi Tool 사용하자.
- 크롤링은 간단한 정보 -> 전문 검색, 백준 사이트 -> 다른 사이트 같이 차근차근 기능을 추가하자.
토이 프로젝트이니 써보고 싶은 것도 하고 싶은게 많습니다만 최대한 줄여서 작성한 목록입니다. 얼추 프로젝트 방향이 정해졌으니 빠른 결과물 + 흥미를 위해 적당히 타협하는 선에서 다음과 같이 계획을 작성했습니다.
- 백준 알고리즘 카테고리별 문제 리스트를 python으로 웹 스크래핑 스크립트 작성하여 콘솔에 출력해본다.
- 출력된 데이터가 유효한지 확인되면 MongoDB에 저장한다.
- BI Tool 를 이용해 데이터를 Visualization(시각화) 한다.
지금부터 토이 프로젝트 초반 기본 과정을 공유하고자 합니다.
1. 백준 알고리즘 사이트 크롤링 가능 여부 확인
가져오고 싶은 데이터는 알고리즘 카테고리 별 문제 리스트입니다. 우선 크롤링하고자 하는 웹사이트의 주소를 확인합니다. 주소를 확인한 결과 제가 크롤링에 사용하게 될 URL은 두 가지로 볼 수 있습니다.
- 알고리즘 분류 URL -> https://www.acmicpc.net/problem/tags
- 알고리즘별 문제 리스트 URL -> https://www.acmicpc.net/problem/tag/{알고리즘 이름}
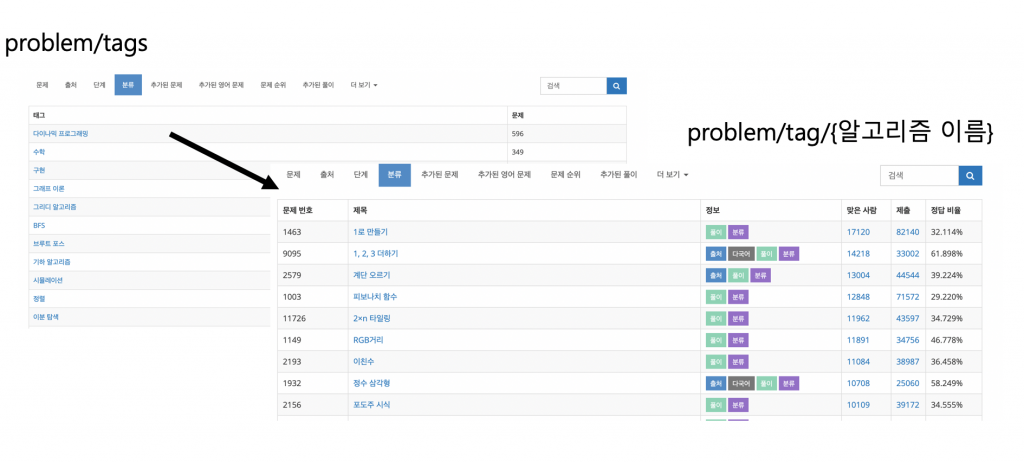
다이나믹 프로그래밍 (/problem/tag/다이나믹프로그래밍)의 알고리즘 리스트를 조회할 수 있다.
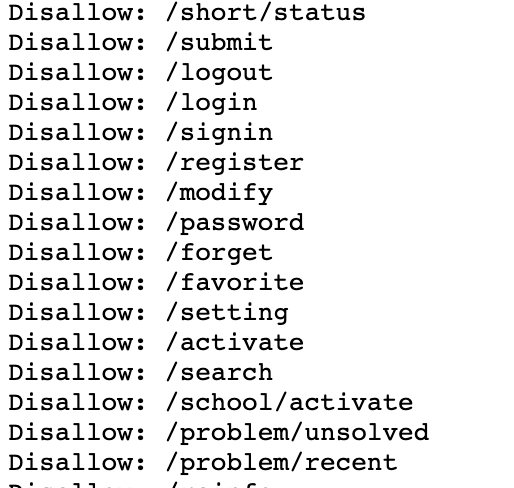
URL를 확인했으니 웹 스크래핑을 시작하면 될까요? 시작에 앞서 가장 중요한 작업이 빠져있습니다. 백준 알고리즘 사이트에서 크롤링 허용가능한지 확인하는 작업이 필요합니다. 크롤링 작업은 타 사이트의 정보를 가져오는 것이라 위법을 항상 경계하면서 작업해야합니다. 보통 웹사이트에서는 Robots.txt에서 크롤링을 허용하지 않는 URL를 명시하고 있기 때문에 이를 참고해야합니다.
도메인 주소 다음 path에 robots.txt를 입력하면 해당 사이트의 크롤링 허용 범위를 알 수 있습니다. 로그인이 필요없는 문제 리스트였기에 제가 크롤링하고자 하는 두 개의 Url은 Disallow 명단에 없었습니다. 위법이 아니니 마음놓고 크롤링을 진행해 보도록 하겠습니다.
2. 웹 스크래핑 스트립트 코드 작성
우선, 해당 데이터를 콘솔 화면에 보여주는 것을 목표로 삼고 웹 스크래핑 코드를 작성하겠습니다. 이전 포스팅에서는 Beautiful4 package를 사용해보았었는데 이번 웹 스크래핑 프로젝트에서는 웹 브라우저를 좀 더 자유롭고 쉽게 다룰 수 있는 Selenium python 패키지를 사용하여 웹 스크래핑을 진행하겠습니다. 스크래핑 순서는 다음과 같이 진행할 예정입니다.
- selenium 설치 및 Web Driver 설치
- 알고리즘 카테고리 리스트 출력
- 카테고리별 알고리즘 출력
- 해당 데이터 DB 저장
python 스크래핑에 익숙하지 않은 분들은 python 웹 스크래핑 이전 포스팅을 참조하는 것을 추천드립니다 .
2-1. selenium 설치 및 Web Driver 설치
우선, 패키지 관리자 pip를 사용하여 selenium 패키지를 설치합니다.
pip install selenium
다음, Web Driver를 설치해야합니다. Web Driver는 웹 브라우저를 제어하는 드라이버, 툴 입니다. 사용하고자하는 브라우저에 맞는 웹 드라이버를 설치하시면 됩니다. 저는 크롬 브라우저를 사용하고자 합니다. 아래 주소에서 크롬 드라이버를 다운받아 설치하시면 됩니다.
- 크롬 웹 드라이버 설치 주소 : https://sites.google.com/a/chromium.org/chromedriver/downloads
2-2. 알고리즘 카테고리 리스트 출력
우선, 백준 사이트 알고리즘 분류 (URL : https://www.acmicpc.net/problem/tags)에서 알고리즘 카테고리만 뽑아 출력해보겠습니다.
알고리즘 분류 페이지에서 가져오고 싶은 것은 단지 카테고리 이름입니다. 크롬 개발자 툴을 사용하여 우리가 얻고 싶은 알고리즘 카테고리 위치를 분석하겠습니다. table > tr > td > a 이런 식으로 카테고리 명이 존재하는 것을 알 수 있습니다.

코드를 작성해 콘솔창에 알고리즘 분류를 모두 출력해보겠습니다.
from selenium import webdriver
backJoonCategoryUrl = "https://www.acmicpc.net/problem/tags";
# selenium webdriver
browser = webdriver.Chrome();
# 문제 분류 초기페이지
browser.get(backJoonCategoryUrl);
# 카테고리 tr태그 한 줄 묶음으로 분류
categorys = browser.find_elements_by_css_selector('table.table.table-bordered.table-striped tbody tr');
categoryNames = []
for category in categorys:
categoryName = category.find_element_by_css_selector('td > a').text
categoryNames.append(categoryName)
print(categoryNames)
해당 코드를 실행하는 하면 다음과 같은 결과를 얻을 수 있습니다.

2-3. 카테고리별 알고리즘 리스트 출력
모든 알고리즘 리스트를 알 수 있게되었습니다. 다음 단계로 카테고리별 알고리즘 리스트를 출력하고자 합니다. 카테고리별 알고리즘 리스트에 해당하는 URI은 아래와 같습니다. ‘https://www.acmicpc.net/problem/tag/’ + 카테고리명이라는 형태라는 것을 알 수 있습니다.

카테고리 분류를 모두 알았으니 카테고리 별 알고리즘 리스트 페이지를 모두 순회하면서 알고리즘 정보를 출력하겠습니다. 방법은 위의 카테고리 분류들을 가져오는 것과 크게 다르지 않습니다. 코드는 다음과 같습니다.
from selenium import webdriver
backJoonCategoryUrl = "https://www.acmicpc.net/problem/tags";
# selenium webdriver
browser = webdriver.Chrome();
# 문제 분류 초기페이지
browser.get(backJoonCategoryUrl);
categorys = browser.find_elements_by_css_selector('table.table.table-bordered.table-striped tbody tr');
categoryNames = []
for category in categorys:
categoryName = category.find_element_by_css_selector('td > a').text
categoryNames.append(categoryName)
for categoryN in categoryNames:
browser.get('https://www.acmicpc.net/problem/tag/' + categoryN)
trs = browser.find_elements_by_css_selector('table#problemset tbody tr')
for tr in trs:
bj_num = tr.find_element_by_css_selector('td.list_problem_id').text
title = tr.find_element_by_css_selector('td:nth-child(2)').text
solvers = tr.find_element_by_css_selector('td:nth-child(4)').text
submitCnt = tr.find_element_by_css_selector('td:nth-child(5)').text
solveRate = tr.find_element_by_css_selector('td:nth-child(6)').text
print("{0} {1} {2} {3} {4}".format(bj_num, title, solvers, submitCnt, solveRate))
알고리즘을 백준 알고리즘 번호, 제목, 푼 사람 수, 제출 수, 정답비율 별로 출력할 수 있습니다. 실행 결과는 다음과 같습니다.
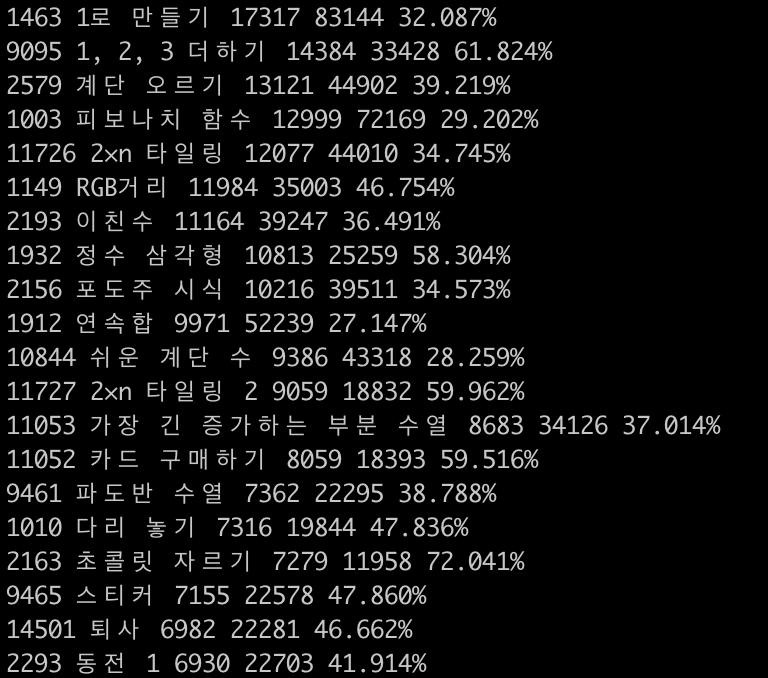
해당 알고리즘 수가 많아 스크래핑이 만족할만한 수준의 속도로는 조회할 수 없지만 가져오고자 하는 정보를 모두 조회할 수 있어서 만족합니다. 스크래핑의 속도를 좀 더 빠르게 하고 싶은 분들은 python thread 를 사용하여 분산 처리하면 빠른 속도로 모든 리스트들을 얻을 수 있습니다.
마침
이번 포스팅을 통해 간단한 토이 알고리즘 크롤링 프로젝트를 기획부터 selenium과 web driver를 통해 웹 스크래핑을 통해 결과물까지 얻어보았습니다. 다음 포스팅에서는 얻은 결과물을 DB 에 저장하고 BI Tool 를 통해 시각화하는 것까지 공유하고자 합니다. 제 포스팅들이 부족한 점이 많지만 항상 도움이 되었으면 합니다.
Fantastic blog! Do you have any tips for aspiring writers? Erminie Antin Kopp